
About
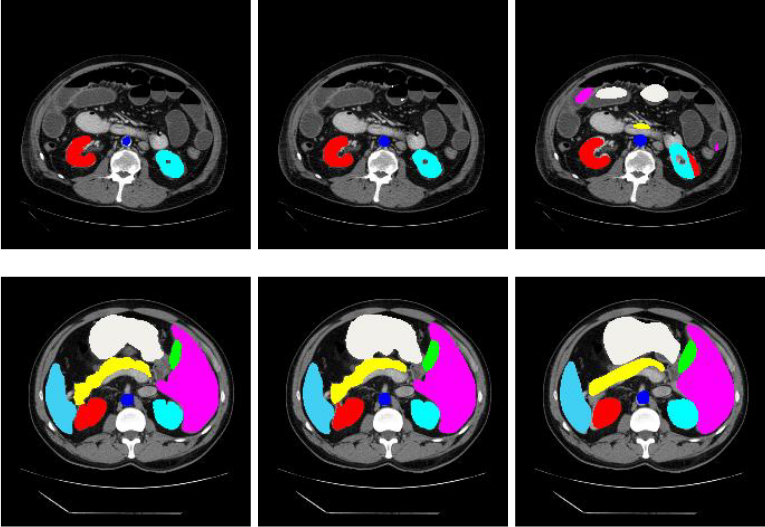
Training process for TransUNet model.
Training process for TransUNet model. This algorithm can train TransUNet model for semantic segmentation.
🚀 Use with Ikomia API
1. Install Ikomia API
We strongly recommend using a virtual environment. If you're not sure where to start, we offer a tutorial here.
2. Create your workflow
☀️ Use with Ikomia Studio
Ikomia Studio offers a friendly UI with the same features as the API.
-
If you haven't started using Ikomia Studio yet, download and install it from this page.
-
For additional guidance on getting started with Ikomia Studio, check out this blog post.
📝 Set algorithm parameters
- input_size (int) - default '256': Size of the input image.
- epochs (int) - default '15': Number of complete passes through the training dataset.
- batch_size (int) - default '1': Number of samples processed before the model is updated.
- learning_rate (float) - default '0.01': Step size at which the model's parameters are updated during training.
- output_folder (str, optional): path to where the model will be saved.
- num_workers (int) - default '0': How many parallel subprocesses you want to activate when you are loading all your data during your training or validation.
- weight_decay (float) - default '1e-4': Amount of weight decay, regularization method.
- eval_period (int) - default '100: Interval between evaluations.
- max_iter (int) - default '1000': Maximum number of iterations.
- early_stopping (bool) - default 'False': Activate early stopping callback to avoid over fitting.
- dataset_split_ratio (int) – default '90' ]0, 100[: Divide the dataset into train and evaluation sets.
- patch_size (int) - default '16': Path size of the ViT model.
Parameters should be in strings format when added to the dictionary.
Developer

Ikomia
License
Apache License 2.0
A permissive license whose main conditions require preservation of copyright and license notices. Contributors provide an express grant of patent rights. Licensed works, modifications, and larger works may be distributed under different terms and without source code.
| Permissions | Conditions | Limitations |
|---|---|---|
Commercial use | License and copyright notice | Trademark use |
Modification | State changes | Liability |
Distribution | Warranty | |
Patent use | ||
Private use |
This is not legal advice: this description is for informational purposes only and does not constitute the license itself. Provided by choosealicense.com.